Python Data Structures
A data structure serves as a fundamental concept in computer science, acting as a container that systematically organizes and arranges data in a specific layout. Each data structure is thoughtfully designed to accommodate data in a manner that aligns with a particular purpose or objective, enabling efficient access, manipulation, and processing of the data. The selection and design of a data structure are contingent upon the nature of the data and the specific operations that need to be performed on it. Whether it be arrays, linked lists, stacks, queues, trees, graphs, or hash tables, each data structure possesses its own set of characteristics and functionalities, tailoring the organization of data to optimize performance and streamline operations. Python has the following built-in data structures:
- List (Mutable Arrays)
- Tuple (Immutable Arrays)
- Dictionary (Hashtables)
- Sets
List
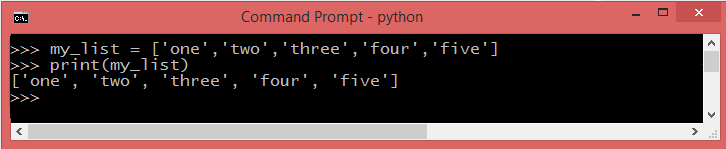
List (Mutable Arrays) in Python is one of the most frequently used and very versatile data structure. Python Lists are mutable, this means that the list elements can be changed unlike string or tuple. It can be created using square brackets[] and allows duplicate members.
Tuple
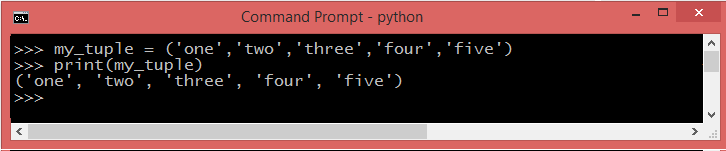
A Tuple is a collection with round brackets() separated by commas which is ordered and unchangeable. Tuples are just like lists in terms of indexing, nested objects and repetition but you cannot change the elements of a tuple once it is assigned unlike lists, elements can be changed.
Dictionary
Dictionaries, in Python, are used to store values in {key:value} pairs. Keys in Dictionaries are unique and values may not be. Dictionaries are indexed by keys and each key can be "map" or "associate" to value objects. Each key in dictionary is separated from its value by a : (colon), the items are separated by commas, and the key and value is enclosed in {} (curly braces).
Sets
Sets in Python are used to store unordered collection data type in a single variable and has no duplicate elements. Sets are typically used for mathematical operations like union, intersection, difference and complement etc.
Conclusion
By choosing the appropriate data structure, programmers can ensure that data is stored, retrieved, and manipulated in a manner that best suits the requirements of their applications, ultimately culminating in a more efficient, reliable, and scalable codebase.