A Beginners Guide to Scikit-Learn
Scikit-learn is a fundamental Python library for data analysis, known for its simplicity, efficiency, and accessibility. As an open-source package, it aims to make machine learning accessible to non-specialists using a general-purpose high-level language. The library primarily focuses on data processing, analysis, and modeling, boasting minimal dependencies and distributed under the permissive Berkeley Source Distribution (BSD) license, encouraging its adoption in both organizational and academic settings. Due to its integration with the scientific Python environment, Scikit-learn can be easily incorporated into projects beyond the scope of traditional statistical data analysis.
Installing scikit-learn
A simple machine learning model using Scikit Learn
Step by Step explanation...
Load wine data set
The wine dataset is a classic and very easy multi-class classification dataset .
Logistic Regression classifier
Logistic regression is a fundamental classification technique used for binary classification tasks. Although it is part of the linear classifiers family, it differs from polynomial and linear regression as it is specifically designed for categorical outcomes. In Scikit-learn, to utilize logistic regression, one must create a logistic regression estimator object, which can then be used to fit the model to the data and make predictions for classification tasks.
train_test_split Function
The train_test_split() function in Scikit-learn is a convenient tool for splitting a single dataset into two separate subsets. One subset is used for training the machine learning model, and the other subset is used for testing the model's performance and evaluating its accuracy. By creating distinct training and testing datasets, it allows for a robust assessment of the model's generalization capabilities and helps prevent overfitting.
fit() method
The fit() method in Scikit-learn is used to train a machine learning model using the dataset provided during the training phase. It is a crucial step in the modeling process, where the model learns from the training data and adjusts its parameters to make accurate predictions. After the fit() method is called, the model is ready to be used for making predictions on new data during the testing or inference phase.
predict() method
After the machine learning model is trained using the fit() method, it can be utilized to make predictions on new, unseen data. The predict() method in Scikit-learn allows the model to generate predictions based on the learned patterns from the training data. This predictability on new data is one of the key advantages of machine learning models, enabling them to be applied to real-world scenarios for making informed decisions and solving various problems.
Random forest classifier
Random Forest is an ensemble learning technique that builds multiple decision trees on randomly selected subsets of the data. Each tree provides predictions, and in the case of classification tasks, the final prediction is determined by majority voting among the individual tree predictions. This process helps improve the model's accuracy, generalization, and robustness, making Random Forest a powerful and popular machine learning algorithm.
Simple Imputer
SimpleImputer is a useful class in Scikit-learn that helps handle missing data in predictive model datasets. It allows you to replace the NaN (Not a Number) values in the dataset with a specified placeholder or strategy, such as mean, median, most frequent value, or a constant value. This imputation process is crucial for preparing the data before building predictive models, as missing data can lead to biased or inaccurate results.
Model Evaluation
Model evaluation is a crucial step in the machine learning workflow, and it involves measuring the performance of the trained model on new, unseen data. The choice of evaluation metric depends on the specific task you are trying to solve, such as classification, regression, or clustering. Common evaluation metrics include accuracy, precision, recall, F1-score, mean squared error, and many others. Selecting an appropriate evaluation metric is essential for assessing how well the model generalizes to real-world data and helps in making informed decisions about the model's effectiveness for the given task.
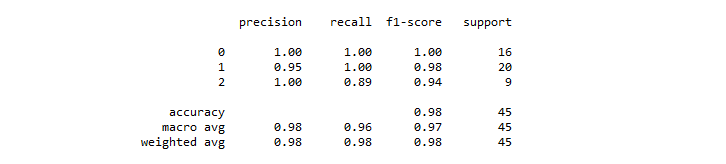
Classification Report
A classification report is a useful tool to evaluate the quality of predictions from a classification algorithm. It provides a detailed summary of the model's performance by displaying metrics such as precision, recall, F1-score, and support for each class in the classification task. These metrics help assess the accuracy and reliability of the model's predictions, making it easier to understand its strengths and weaknesses for different classes in the dataset. The classification report is an essential part of model evaluation and aids in making informed decisions about the model's effectiveness in a classification problem.
The classification report is about key metrics in a classification problem .
| Heading | Description |
|---|---|
| precision | how many are correctly classified among that class |
| recall | how many of this class you find over the whole number of element of this class |
| f1-score | harmonic mean between precision and recall |
| support | number of occurence of the given class in your dataset |
Conclusion
Scikit-learn is a fundamental Python library for machine learning and data analysis. With its simplicity, efficiency, and broad range of functionalities, Scikit-learn offers accessible and powerful tools for building and evaluating machine learning models in various data science tasks.