New dataframe column based on a given condition
There are instances where data analysts and scientists aspire to augment a DataFrame by introducing a new column, contingent upon certain conditions or logical expressions. This powerful technique arises when data professionals seek to derive supplementary insights or categorical classifications from existing data, paving the way for enriched data representations and more informed analyses.
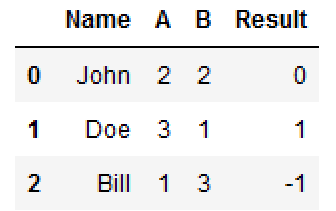
Suppose you have a DataFrame like this:
You want to create a new column "Result" based on the following condition:
- A == B: 0
- A > B: 1
- A < B: -1
So, by applying above condition, DataFrame should be:
While the notion of crafting a new DataFrame column based on specific conditions is prevalent in data analysis workflows, it is essential to recognize that Pandas does not offer a direct, dedicated library function to execute this operation effortlessly. Instead, data professionals can ingeniously employ a combination of Pandas' versatile functionalities and Pythonic constructs to tailor the DataFrame to their precise requirements.
How to achieve above condition through Pandas DataFrameoperation?
Lets create a DataFrame..
Vectorized Version
Using if..else
Python's native conditional statements, such as if and else, offer further flexibility in setting up intricate decision trees that govern the new column's content. This enables the crafting of complex conditions that span multiple columns or incorporate mathematical operations, maintaining data-driven insights with comprehensiveness and finesse.
Operation on Single column
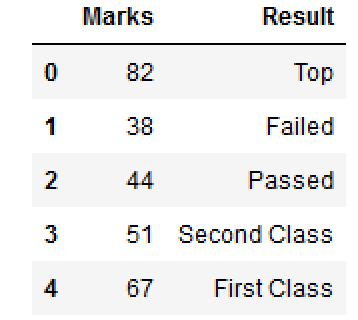
Suppose, you have a DataFrame like this:
You would like to add one more column for Result based on certain conditions.
- Marks <= 30 : Failed
- Marks >= 40 and <=49 : Passed
- Marks >= 50 and <=59 : Second Class
- Marks >= 60 and <=79 : First Class
- Marks >= 80 and <=100 : Top
How you can create a dataFrame column based on the above condition using DataFrame.loc[] .
Conclusion
While Pandas may not offer a specialized function for creating new DataFrame columns based on conditions, the library's inherent extensibility and Python's versatile programming constructs empower data professionals to accomplish this task with elegance and efficiency. By ingeniously combining Pandas' data manipulation prowess with native Python capabilities, data professionals can elevate the DataFrame's analytical potential, unravel hidden patterns, and make data-informed decisions with precision and rigor. This amalgamation of tools ensures that the possibilities for enriching and expanding DataFrame representations are boundless, reinforcing Pandas' standing as a stalwart companion in the quest for data-driven knowledge.
- Pandas DataFrame: GroupBy Examples
- Pandas DataFrame Aggregation and Grouping
- How to Sort Pandas DataFrame
- Pandas DataFrame: query() function
- Finding and removing duplicate rows in Pandas DataFrame
- How to Replace NaN Values With Zeros in Pandas DataFrame
- How to read CSV File using Pandas DataFrame.read_csv()
- How to Convert Pandas DataFrame to NumPy Array
- How to shuffle a DataFrame rows
- Import multiple csv files into one pandas DataFrame
- Create new column in DataFrame based on the existing columns
- How to Convert a Dictionary to Pandas DataFrame
- Rename Pandas columns/index names (labels)
- Check for NaN Values : Pandas DataFrame