New Pandas column based on other columns
One of the most empowering and common operations entails creating a new column in a DataFrame based on the values of existing columns. This invaluable technique opens a gateway to unleashing deeper insights from data, enabling data analysts and scientists to engineer and derive novel features or metrics that complement the original dataset. You can use the following methods to create new column based on values from other columns:
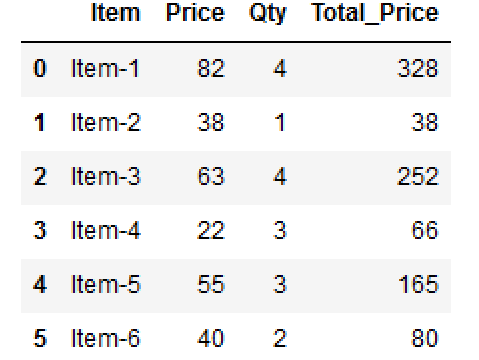
Lets create a DataFrame..
Using simple DataFrame multiplication
Using df.apply()
The df.apply() is a powerful and versatile method used to apply a function along either the rows or columns of a DataFrame. This method allows data professionals to perform custom operations or calculations on the DataFrame's data, facilitating data transformation, cleaning, or feature engineering with efficiency and precision.
The syntax for df.apply() is as follows:
Example:
Using np.multiply()
The np.multiply() is a fundamental function used to perform element-wise multiplication on arrays. This versatile function allows data professionals to multiply corresponding elements of one or more arrays, aligning their dimensions for consistent and accurate calculations.
The syntax for np.multiply() is as follows:
Example:
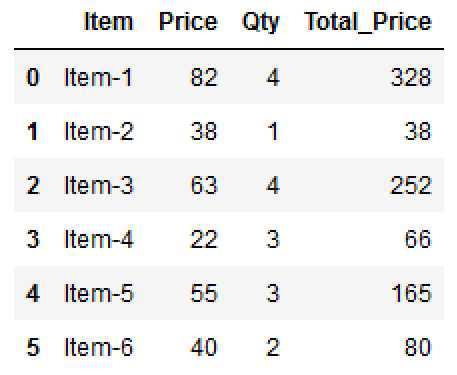
Using vectorize arbitrary function
You can vectorize an arbitrary function using the np.vectorize() function. This process involves transforming a Python function that operates on scalars into a vectorized function that can work element-wise on arrays. By vectorizing a function, you can apply it to NumPy arrays directly, allowing for efficient element-wise computations without the need for explicit loops.
The np.vectorize() function takes an input function and returns a new function that can operate on arrays. It uses NumPy's broadcasting capabilities to apply the function to each element of the input arrays, making it well-suited for element-wise operations.
Example:
Conclusion
The process of crafting a new Pandas column based on other columns constitutes an artful fusion of creativity and data science acumen. By sensibly using the vast array of Pandas' data transformation capabilities, data professionals can transcend the boundaries of raw data and forge a tapestry of insightful metrics and features that unravel the true potential of the dataset. This approach stands as an indispensable instrument in the data analyst's toolkit, exemplifying the boundless potential of Pandas in transforming data into actionable knowledge and driving data-driven solutions with ingenuity and finesse.
- Pandas DataFrame: GroupBy Examples
- Pandas DataFrame Aggregation and Grouping
- How to Sort Pandas DataFrame
- Pandas DataFrame: query() function
- Finding and removing duplicate rows in Pandas DataFrame
- How to Replace NaN Values With Zeros in Pandas DataFrame
- How to read CSV File using Pandas DataFrame.read_csv()
- How to Convert Pandas DataFrame to NumPy Array
- How to shuffle a DataFrame rows
- Import multiple csv files into one pandas DataFrame
- New Pandas dataframe column based on if-else condition
- How to Convert a Dictionary to Pandas DataFrame
- Rename Pandas columns/index names (labels)
- Check for NaN Values : Pandas DataFrame