Randomly Shuffle DataFrame Rows in Pandas
In the scope of data manipulation using Pandas, a noteworthy capability that elevates the flexibility of data exploration and analysis lies in the process of randomly shuffling DataFrame rows. This powerful operation empowers data professionals to reorder the rows of a DataFrame in a non-deterministic fashion, introducing an element of randomness that enables statistical significance and maintains robustness in subsequent analyses. You can use the following methods to shuffle DataFrame rows:
- Using pandas
- Using numpy
- Using sklearn
The act of randomly shuffling DataFrame rows entails rearranging the order of data observations in a manner that bears no predetermined pattern, offering an unbiased representation of the dataset. This randomness is particularly advantageous when dealing with data that might have inherent ordering or when preparing data for training machine learning models that benefit from diverse and unpredictable sequences.
Lets create a DataFrame..
pandas.DataFrame.sample()
By employing the sample() method with the frac parameter set to 1 (indicating that all rows should be included) and replace parameter set to False (to ensure that no row is repeated), data professionals can confidently shuffle the DataFrame rows. This method guarantees an equitable distribution of rows, maintaining equitable representation of the dataset while preserving its inherent characteristics.
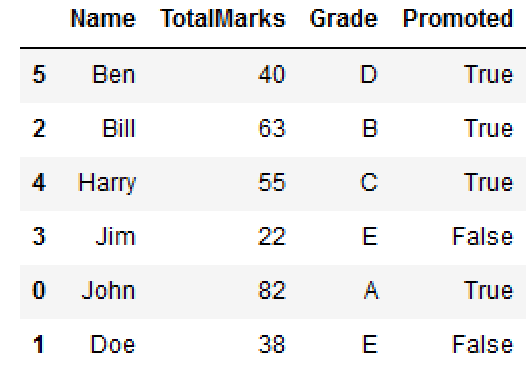
Argument frac=1 means return all rows.
If you wish to shuffle your dataframe in-place and reset the index, you could do e.g.
By using the sample() method with the frac parameter set to 1 (indicating that all rows should be included) and replace parameter set to False (to ensure that no row is repeated), data professionals can confidently shuffle the DataFrame rows. This method guarantees an equitable distribution of rows, maintaining equitable representation of the dataset while preserving its inherent characteristics.
numpy.random.permutation()
Here, specifying drop=True prevents .reset_index from creating a column containing the old index entries.
The significance of random shuffling extends beyond exploratory data analysis, as it plays a key role in cross-validation procedures, enabling rigorous model assessment and selection. By employing random shuffling in the cross-validation, data professionals can obtain unbiased estimations of model performance, thereby gaining a comprehensive understanding of model effectiveness on diverse datasets.
sklearn.utils.shuffle()
Conclusion
The ability to randomly shuffle DataFrame rows in Pandas exemplifies the adaptability and versatility of this data manipulation library. The randomness introduced by this operation promotes data integrity, unbiased analyses, and robust model assessment, enriching the data analysis landscape with a layer of unpredictability that unveils new insights and strengthens data-driven decision-making processes. By using the power of random shuffling, data professionals can confidently navigate the complexities of their datasets and unravel meaningful patterns that inspire innovative solutions and drive transformative outcomes.
- Pandas DataFrame: GroupBy Examples
- Pandas DataFrame Aggregation and Grouping
- How to Sort Pandas DataFrame
- Pandas DataFrame: query() function
- Finding and removing duplicate rows in Pandas DataFrame
- How to Replace NaN Values With Zeros in Pandas DataFrame
- How to read CSV File using Pandas DataFrame.read_csv()
- How to Convert Pandas DataFrame to NumPy Array
- Import multiple csv files into one pandas DataFrame
- Create new column in DataFrame based on the existing columns
- New Pandas dataframe column based on if-else condition
- How to Convert a Dictionary to Pandas DataFrame
- Rename Pandas columns/index names (labels)
- Check for NaN Values : Pandas DataFrame